Examples
Numerical Simulators
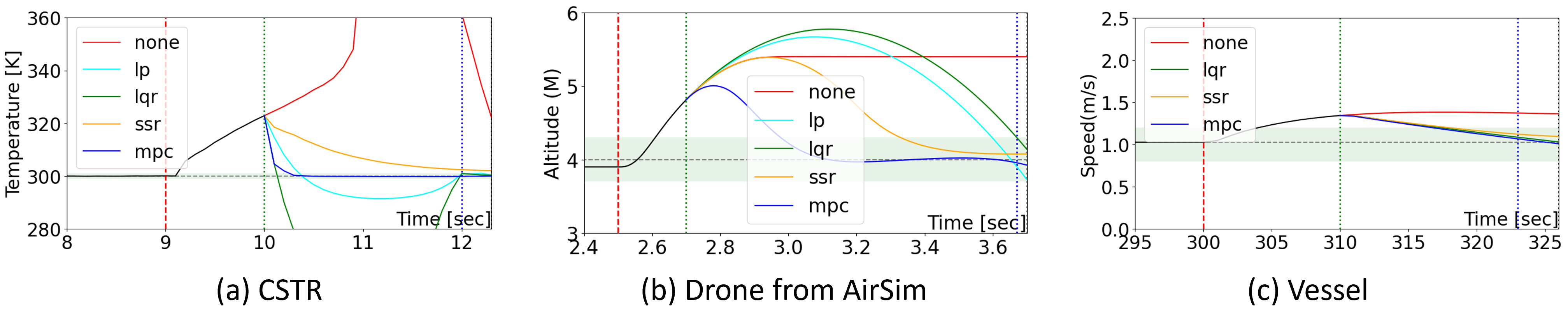
In this file, we choose a benchmark plant, CSTR shown in the following figure, controlled by a PID controller. Also, we define the bias sensor attack that subtracts 25K from the temperature sensor feedback starting from the ninth second. The detector identifies the attack at the 10th second, and triggers the recovery controllers. Baseline recovery controllers include (i) no recovery method (none), (ii) software-sensor-based recovery (ssr [1]_), (iii) linear-quadratic-regulator-based recovery (lqr [2]_), and (vi) data-predictive recovery (mpc [3]_).
First, we aim to evaluate the recovery performance of different baseline recovery controllers. We only require modifying the configuration file rather than writing simulation code. In this file, we use three benchmark plants, CSTR, quadrotor and Vessel, controlled by a PID controller. Also, we define the bias sensor attack. The detector identifies the attack after the attack happends and triggers the recovery controllers. Baseline recovery controllers include (i) no recovery method (none), (ii) software-sensor-based recovery (ssr [1]_), (iii) linear-quadratic-regulator-based recovery (lqr [2]_), and (vi) data-predictive recovery (mpc [3]_).
The following figure plots the results from the simulator. From the curve, we can intuitively analyze the recovery performance of each baseline recovery controller.
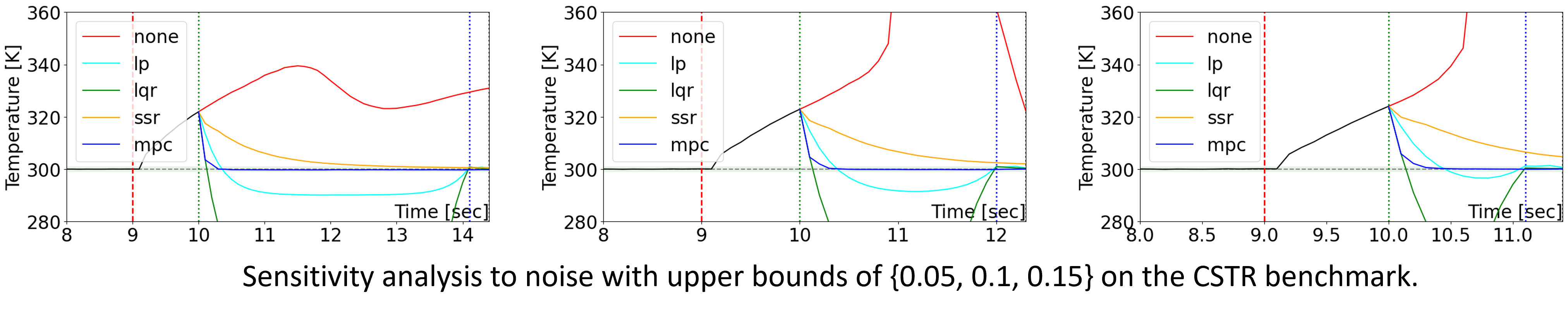
We conduct a sensitivity analysis by varying bias values and noise on the CSTR benchmark. The findings are displayed in the two figures below.

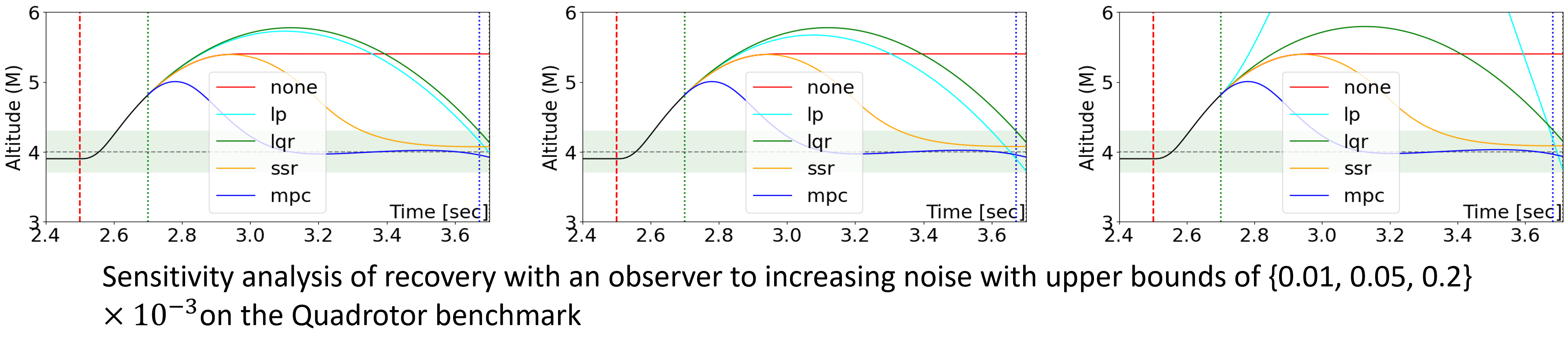
We also provide the sensitivity analysis by the noise with varying upper bound on the quadrotor benchmark.
We provide the source code of above figures.
1import numpy as np
2class cstr_bias:
3 name = 'cstr_bias' # benchmark name
4 max_index = 180 # simulation time period
5 ref = [np.array([0.98189, 300.00013])] * (max_index + 1) # reference state
6 dt = 0.1 # sampling time
7 noise = {
8 'process': { # process/sensor disturbance
9 'type': 'box_uniform',
10 'param': {'lo': np.array([0, 0]), 'up': np.array([0.15, 0.15])} # the intensity of disturbance
11 }
12 }
13 # noise = None
14 model = CSTR(name, dt, max_index, noise=noise) # benchmark model (defined in simulators folder)
15 ode_imath = cstr_imath # model for interval arithmetic
16
17 attack_start_index = 90 # index when attack starts
18 recovery_index = 100 # index when recovery starts
19 bias = np.array([0, -30]) # bias sensor attack intensity
20 unsafe_states_onehot = [0, 1] # indicate which state is unsafe / affected by attack
21 attack = Attack('bias', bias, attack_start_index) # attack type and intensity
22
23 output_index = 1 # index in state to be plotted
24 ref_index = 1 # index in state to be plotted
25
26 safe_set_lo = np.array([-5, 250]) # safe set lower bound
27 safe_set_up = np.array([5, 360]) # safe set upper bound
28 target_set_lo = np.array([-5, 299]) # target set lower bound
29 target_set_up = np.array([5, 301]) # target set upper bound
30 control_lo = np.array([200]) # control lower bound
31 control_up = np.array([300]) # control upper bound
32 recovery_ref = np.array([0.98189, 300.00013]) # recovery target state
33
34 # Q = np.diag([1, 1])
35 # QN = np.diag([1, 1])
36 Q = np.diag([1, 1000]) # state cost for LQR or MPC
37 QN = np.diag([1, 1000]) # final state cost for LQR or MPC
38 R = np.diag([1]) # control cost for LQR or MPC
39
40 MPC_freq = 1 # optimization frequency
41 nx = 2 # state dimension
42 nu = 1 # control dimension
43
44 # plot
45 y_lim = (280, 360) # y axis range to be plotted
46 x_lim = (8, dt * 200) # x axis range to be plotted
47 strip = (target_set_lo[output_index], target_set_up[output_index]) # strip to be plotted
48 y_label = 'Temperature [K]' # y axis label
49
50 # for linearizations for baselines, find equilibrium point and use below
51 u_ss = np.array([274.57786]) # equilibrium control for baseline only
52 x_ss = np.array([0.98472896, 300.00335862]) # equilibrium state for baseline only
Reference:
Fast Attack Recovery for Stochastic Cyber-Physical Systems
We present the simulations for the Fast Attack Recovery for Stochastic Cyber-Physical Systems paper [4]. We propose the solution to the Optimal probabilistic recovery (OPR). We use the linear model of a motor as an example. For the experiments in the paper, we simulate a bias attack against the motor angular speed measurement by adding a bias of -1m/s. The adversary deploys the attack at time 3s after beginning the simulation, and the detector identifies the attack one second later. This alarm triggers the recovery strategies.
We compare the performance of our solution, called the open loop OPR (OPR-OL), with the LQR-based recovery [2]_, and virtual sensors. We then obtain the next Figure:
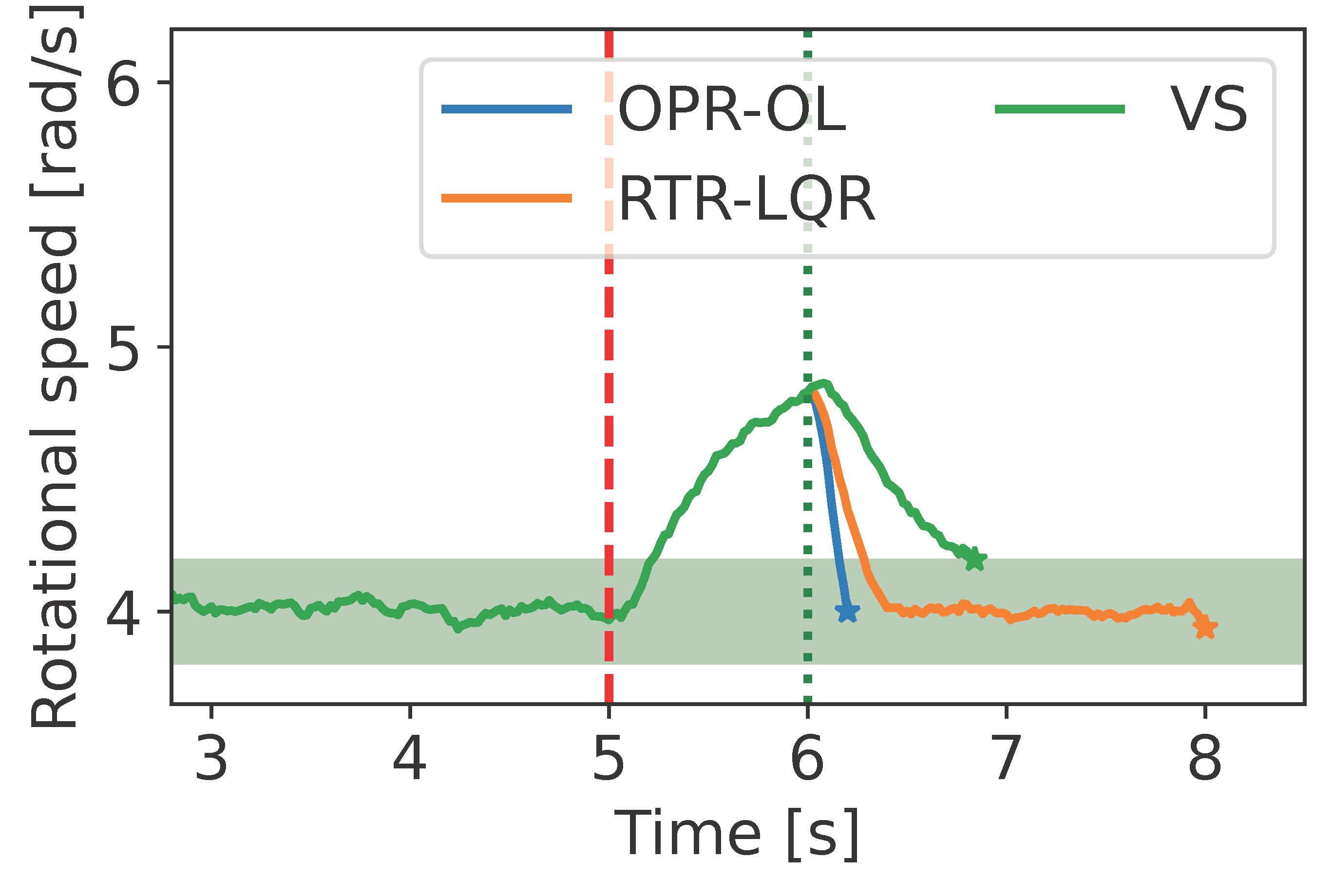
We also include the simulations to improve our solution by incorporating the non-compromised sensors into the recovery. We call this strategy the partially closed loop OPR (OPR-PCL). We compare the OPR-OL and OPR-PCL:
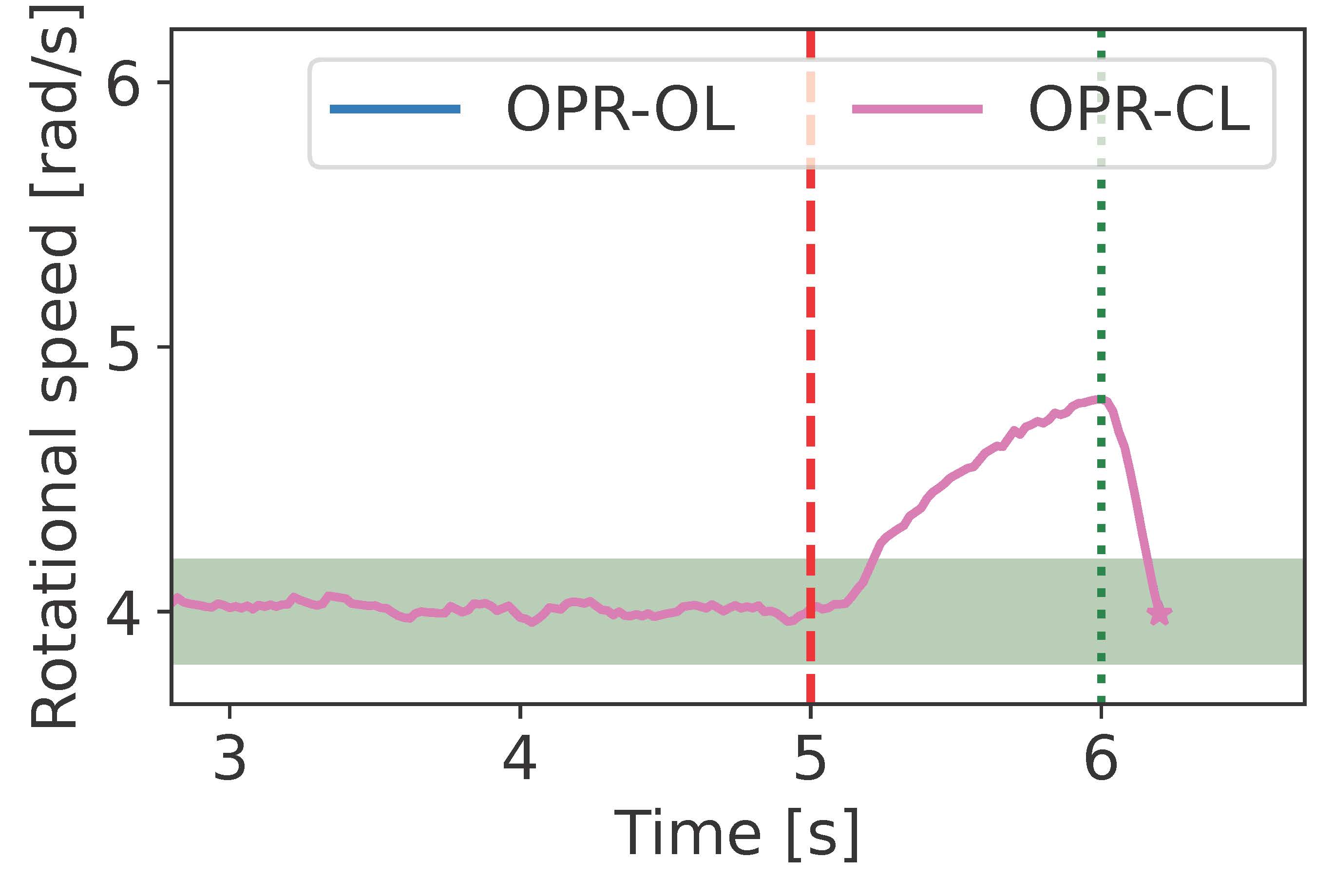
We provide the code to obtain previous figures.
1'''
2This file implements the simulation of real-time recovery linear quadratic regulator (RTR-LQR)
3Virtual sensors (VS), Optimal probabilistic recovery in open loop (OPR-OL) and closed loop (OPR-CL)
4'''
5
6from copy import deepcopy
7import matplotlib.pyplot as plt
8plt.rcParams.update({'font.size': 15})
9import matplotlib
10matplotlib.rcParams['pdf.fonttype'] = 42
11matplotlib.rcParams['ps.fonttype'] = 42
12
13import numpy as np
14import logging
15import sys
16import os
17import csv
18import time
19from time import perf_counter
20
21os.environ["RANDOM_SEED"] = '0' # for reproducibility
22sys.path.append(sys.path[0] + '/../../')
23
24from cpsim.formal.gaussian_distribution import GaussianDistribution
25from cpsim.formal.reachability import ReachableSet
26from cpsim.formal.zonotope import Zonotope
27from cpsim.observers.kalman_filter import KalmanFilter
28from cpsim.observers.full_state_bound import Estimator
29from cpsim.controllers.LP_cvxpy import LP
30from cpsim.controllers.MPC_cvxpy import MPC
31
32# from cpsim.performance.performance_metrics import distance_to_strip_center, in_strip
33
34def in_strip(l, x, a, b):
35 if l @ x >= a and l @ x <= b:
36 success = 1
37 else:
38 success = 0
39 return success
40
41colors = {'none': 'red', 'lqr': 'C1', 'ssr': 'C2', 'oprp-close': 'C4', 'oprp-open': 'C0'}
42labels = {'none': 'None', 'lqr': 'RTR-LQR', 'ssr': 'VS', 'oprp-close': 'OPR-PCL', 'oprp-open': 'OPR'}
43
44# logger
45logging.basicConfig(
46 format="%(asctime)s [%(levelname)s] %(message)s",
47 handlers=[
48 logging.FileHandler("debug.log"),
49 logging.StreamHandler(sys.stdout)
50 ]
51)
52logger = logging.getLogger(__name__)
53logger.setLevel(logging.DEBUG)
54
55
56
57
58
59
60def save_exp_data(exp, exp_rst, bl, profiling_data = None):
61 '''method to store data'''
62 exp_rst[bl]['states'] = deepcopy(exp.model.states)
63 exp_rst[bl]['outputs'] = deepcopy(exp.model.outputs)
64 exp_rst[bl]['inputs'] = deepcopy(exp.model.inputs)
65 exp_rst[bl]['time'] = {}
66
67 exp_rst[bl]['recovery_steps'] = profiling_data['recovery_steps']
68 exp_rst[bl]['recovery_complete_index'] = profiling_data['recovery_complete_index']
69
70
71
72# --------- attack + no recovery -------------
73def simulate_no_recovery(exp, bl):
74 '''
75 Simulation with attack and no recovery
76 exp: class with the experiment characteristics
77 '''
78 exp.model.reset()
79 exp_name = f" {bl} {exp.name} "
80 logger.info(f"{exp_name:=^40}")
81 for i in range(0, exp.max_index + 1):
82 assert exp.model.cur_index == i
83 exp.model.update_current_ref(exp.ref[i])
84 # attack here
85 exp.model.cur_feedback = exp.attack.launch(exp.model.cur_feedback, i, exp.model.states)
86 exp.model.evolve()
87
88 profiling_data = {}
89 profiling_data["recovery_complete_index"] = exp.max_index + 1
90 profiling_data["recovery_steps"] = exp.max_index - exp.attack_start_index
91
92 return profiling_data
93
94
95# --------- LQR -------------
96def simulate_LQR(exp, bl):
97 '''
98 Simulate the RTR-LQR
99 '''
100 exp_name = f" {bl} {exp.name} "
101 logger.info(f"{exp_name:=^40}")
102 # required objects
103 A = exp.model.sysd.A
104 B = exp.model.sysd.B
105 est = Estimator(A, B, max_k=150, epsilon=1e-7)
106 maintain_time = 3
107 exp.model.reset()
108 # init variables
109 recovery_complete_index = exp.max_index
110 rec_u = None
111
112 elapsed_times = []
113 # Main loop
114 for i in range(0, exp.max_index + 1):
115 assert exp.model.cur_index == i
116 # Obtains reference
117 exp.model.update_current_ref(exp.ref[i])
118 # Launch attack
119 exp.model.cur_feedback = exp.attack.launch(exp.model.cur_feedback, i, exp.model.states)
120 if i == exp.attack_start_index - 1:
121 logger.debug(f'trustworthy_index={i}, trustworthy_state={exp.model.cur_x}')
122 pass
123
124
125 # Check if the recovery begins
126 if i == exp.recovery_index:
127 logger.debug(f'recovery_index={i}, recovery_start_state={exp.model.cur_x}')
128
129 # State reconstruction
130 us = exp.model.inputs[exp.attack_start_index - 1:exp.recovery_index]
131 x_0 = exp.model.states[exp.attack_start_index - 1]
132 x_cur_lo, x_cur_up, x_cur = est.estimate(x_0, us)
133 logger.debug(f'reconstructed state={x_cur}')
134
135 # deadline estimate
136 safe_set_lo = exp.safe_set_lo
137 safe_set_up = exp.safe_set_up
138 control = exp.model.inputs[i - 1]
139 k = est.get_deadline(x_cur, safe_set_lo, safe_set_up, control, 100)
140 recovery_complete_index = exp.recovery_index + k
141 logger.debug(f'deadline={k}')
142 # maintainable time compute
143
144
145 # get recovery control sequence
146 lqr_settings = {
147 'Ad': A, 'Bd': B,
148 'Q': exp.Q, 'QN': exp.QN, 'R': exp.R,
149 'N': k + 3,
150 'ddl': k, 'target_lo': exp.target_set_lo, 'target_up': exp.target_set_up,
151 'safe_lo': exp.safe_set_lo, 'safe_up': exp.safe_set_up,
152 'control_lo': exp.control_lo, 'control_up': exp.control_up,
153 'ref': exp.recovery_ref
154 }
155 lqr = MPC(lqr_settings)
156 _ = lqr.update(feedback_value=x_cur)
157 rec_u = lqr.get_full_ctrl()
158 rec_x = lqr.get_last_x()
159 logger.debug(f'expected recovery state={rec_x}')
160 # Implements the RTR-LQR recovery
161 if i == recovery_complete_index + maintain_time:
162 logger.debug(f'state after recovery={exp.model.cur_x}')
163 step = recovery_complete_index + maintain_time - exp.recovery_index
164 logger.debug(f'use {step} steps to recover.')
165 # Check we need to use the recovery
166 if exp.recovery_index <= i < recovery_complete_index + maintain_time:
167 rec_u_index = i - exp.recovery_index
168 u = rec_u[rec_u_index]
169 exp.model.evolve(u)
170 else: # If not using the recovery, run one step
171 exp.model.evolve()
172 # Store profiling data
173 profiling_data = {}
174 profiling_data["recovery_complete_index"] = recovery_complete_index
175 profiling_data["recovery_steps"] = step
176 return profiling_data
177
178
179# --------- attack + virtual sensors -------------
180def simulate_ssr(exp, bl):
181 '''
182 Implements the software sensors
183 '''
184 # required objects
185 recovery_complete_index = exp.max_index - 1
186 A = exp.model.sysd.A
187 B = exp.model.sysd.B
188 est = Estimator(A, B, max_k=150, epsilon=1e-7)
189 logger.info(f"{bl} {exp.name:=^40}")
190 for i in range(0, exp.max_index + 1):
191 assert exp.model.cur_index == i
192 exp.model.update_current_ref(exp.ref[i])
193 # attack here
194 exp.model.cur_feedback = exp.attack.launch(exp.model.cur_feedback, i, exp.model.states)
195
196 if i == exp.attack_start_index - 1:
197 logger.debug(f'trustworthy_index={i}, trustworthy_state={exp.model.cur_x}')
198 pass
199 if i == exp.recovery_index:
200 logger.debug(f'recovery_index={i}, recovery_start_state={exp.model.cur_x}')
201
202 # State reconstruction
203 us = exp.model.inputs[exp.attack_start_index - 1:exp.recovery_index]
204 x_0 = exp.model.states[exp.attack_start_index - 1]
205 x_cur = est.estimate_wo_bound(x_0, us)
206 logger.debug(f'one before reconstructed state={x_cur}')
207 last_predicted_state = deepcopy(x_cur)
208
209 if exp.recovery_index <= i < recovery_complete_index:
210 # check if it is in target set
211 if in_strip(exp.s.l, last_predicted_state, exp.s.a, exp.s.b):
212 recovery_complete_index = i
213 logger.debug('state after recovery={exp.model.cur_x}')
214 step = recovery_complete_index - exp.recovery_index
215 logger.debug(f'use {step} steps to recover.')
216
217 # Estimate the state using the virtual sensors
218 us = [exp.model.inputs[i - 1]]
219 x_0 = last_predicted_state
220 x_cur = est.estimate_wo_bound(x_0, us)
221
222 # Set the feedback to the state estimated by the virtual sensors
223 exp.model.cur_feedback = exp.model.sysd.C @ x_cur
224 last_predicted_state = deepcopy(x_cur)
225 print(f'{exp.model.cur_u}')
226
227
228 exp.model.evolve()
229
230 profiling_data = {}
231 profiling_data["recovery_complete_index"] = recovery_complete_index
232 profiling_data["recovery_steps"] = recovery_complete_index - exp.recovery_index
233 return profiling_data
234
235
236# --------- attack + OPR-CL -------------
237def simulate_oprp_cl(exp, bl):
238 '''
239 Simulate the OPR-CL
240 exp: class with the experiments characteristics.
241 '''
242 # required objects
243 A = exp.model.sysd.A
244 B = exp.model.sysd.B
245 # Initialize the Kalman filter
246 kf_C = exp.kf_C
247 C = exp.model.sysd.C
248 D = exp.model.sysd.D
249 kf_Q = exp.model.p_noise_dist.sigma if exp.model.p_noise_dist is not None else np.zeros_like(A)
250 kf_R = exp.kf_R
251 kf = KalmanFilter(A, B, kf_C, D, kf_Q, kf_R)
252 # Initialize the zonotopes
253 U = Zonotope.from_box(exp.control_lo, exp.control_up)
254 W = exp.model.p_noise_dist
255 reach = ReachableSet(A, B, U, W, max_step=exp.max_recovery_step )
256
257 # init variables
258 recovery_complete_index = exp.max_index
259 x_cur_update = None
260
261
262
263 logger.info(f" OPR-CL {exp.name} ")
264 for i in range(0, exp.max_index + 1):
265 assert exp.model.cur_index == i
266 exp.model.update_current_ref(exp.ref[i])
267 # attack here
268 exp.model.cur_feedback = exp.attack.launch(exp.model.cur_feedback, i, exp.model.states)
269
270 if i == exp.attack_start_index - 1:
271 logger.debug(f'trustworthy_index={i}, trustworthy_state={exp.model.cur_x}')
272 pass
273
274 # state reconstruct
275 if i == exp.recovery_index:
276 logger.debug(f'recovery_index={i}, recovery_start_state={exp.model.cur_x}')
277 # Obtains the inputs between instant of the attack beginning and the recovery beginning
278 us = exp.model.inputs[exp.attack_start_index-1:exp.recovery_index]
279 # Obtains the measurements.
280 ys = (kf_C @ exp.model.states[exp.attack_start_index:exp.recovery_index + 1].T).T
281 x_0 = exp.model.states[exp.attack_start_index-1]
282 # Use a Kalman filter to estimate the state at the reconfiguration beginning
283 x_res, P_res = kf.multi_steps(x_0, np.zeros_like(A), us, ys)
284 x_cur_update = GaussianDistribution(x_res[-1], P_res[-1])
285 logger.debug(f"reconstructed state={x_cur_update.miu=}, ground_truth={exp.model.cur_x}")
286 # OPR-OL recovery begins
287 # Estimate the probability distribution of the system state
288 if exp.recovery_index < i < recovery_complete_index:
289 x_cur_predict = GaussianDistribution(*kf.predict(x_cur_update.miu, x_cur_update.sigma, exp.model.cur_u))
290 y = kf_C @ exp.model.cur_x
291 x_cur_update = GaussianDistribution(*kf.update(x_cur_predict.miu, x_cur_predict.sigma, y))
292 logger.debug(f"reconstructed state={x_cur_update.miu=}, ground_truth={exp.model.cur_x}")
293
294 if i == recovery_complete_index:
295 logger.debug(f'state after recovery={exp.model.cur_x}')
296 pass
297 # Use the OPR-OL to implement the recovery
298 if exp.recovery_index <= i < recovery_complete_index:
299 # Compute the reachable means
300 reach.init(x_cur_update, exp.s)
301 # Compute the recovery sequence
302 k, X_k, D_k, z_star, alpha, P, arrive = reach.given_k(max_k=exp.max_recovery_step)
303 print(f"{k=}, {z_star=}, {P=}")
304 recovery_control_sequence = U.alpha_to_control(alpha)
305 recovery_complete_index = i+k
306 exp.model.evolve(recovery_control_sequence[0])
307 print(f"{i=}, {recovery_control_sequence[0]=}")
308 else:
309 exp.model.evolve()
310
311 profiling_data = {}
312 profiling_data["recovery_complete_index"] = recovery_complete_index
313 profiling_data["recovery_steps"] = recovery_complete_index - exp.recovery_index
314 return profiling_data
315
316# --------- attack + OPR_OL -------------
317def simulate_oprp_ol(exp, bl):
318 '''
319 function to simulate the OPR-OL strategy.
320 exp: the experiment settings class
321 '''
322 # required objects
323 A = exp.model.sysd.A
324 B = exp.model.sysd.B
325 C = exp.model.sysd.C
326 U = Zonotope.from_box(exp.control_lo, exp.control_up)
327 W = exp.model.p_noise_dist
328 reach = ReachableSet(A, B, U, W, max_step=exp.max_recovery_step )
329
330 # init variables
331 recovery_complete_index = exp.max_index
332 x_cur_update = None
333 exp_name = f" OPR-OL {exp.name} "
334 logger.info(f"{exp_name:=^40}")
335 for i in range(0, exp.max_index + 1):
336 assert exp.model.cur_index == i
337 exp.model.update_current_ref(exp.ref[i])
338 # attack here
339 exp.model.cur_feedback = exp.attack.launch(exp.model.cur_feedback, i, exp.model.states)
340 if i == exp.attack_start_index - 1:
341 logger.debug(f'trustworthy_index={i}, trustworthy_state={exp.model.cur_x}')
342 pass
343
344 # state reconstruct
345 if i == exp.recovery_index:
346 us = exp.model.inputs[exp.attack_start_index - 1:exp.recovery_index]
347 x_0 = exp.model.states[exp.attack_start_index - 1]
348 x_0 = GaussianDistribution(x_0, np.zeros((exp.model.n, exp.model.n)))
349 reach.init(x_0, exp.s)
350 x_res_point = reach.state_reconstruction(us)
351 print('x_0=', x_res_point)
352
353 reach.init(x_res_point, exp.s)
354 k, X_k, D_k, z_star, alpha, P, arrive = reach.given_k(max_k=exp.k_given)
355 recovery_complete_index = exp.recovery_index + k
356 rec_u = U.alpha_to_control(alpha)
357
358 print('k=', k, 'P=', P, 'z_star=', z_star, 'arrive=', arrive)
359 print('D_k=', D_k)
360 print('recovery_complete_index=', recovery_complete_index)
361 print(rec_u)
362
363 if exp.recovery_index <= i < recovery_complete_index:
364 rec_u_index = i - exp.recovery_index
365 u = rec_u[rec_u_index]
366 exp.model.evolve(u)
367 else:
368 exp.model.evolve()
369
370 profiling_data = {}
371 profiling_data["recovery_complete_index"] = recovery_complete_index
372 profiling_data["recovery_steps"] = recovery_complete_index - exp.recovery_index
373
374 return profiling_data
375
376def plot_ts(strategies, exp, exp_rst):
377 plt.figure(figsize=(5,3))
378 max_t = 0
379 for strategy in strategies:
380 #
381 states = exp_rst[strategy]["states"]
382 t = np.arange(0, len(states)) * exp.dt
383
384 states = states[0:exp_rst[strategy]["recovery_complete_index"] + 1]
385 t = t[0:exp_rst[strategy]["recovery_complete_index"] + 1]
386 max_t = np.maximum(t[-1], max_t)
387 #
388 plt.plot(t, states[:, 0], color=colors[strategy], label=labels[strategy], linewidth=2)
389 plt.plot(t[-1], states[-1, 0], color=colors[strategy], marker='*', linewidth=8)
390 # Plot limits in x
391 axes = plt.gca()
392 x_lim = axes.get_xlim()
393 plt.xlim(exp.x_lim[0], max_t + 0.5)
394
395 # Plot limits in y
396 plt.ylim(exp.y_lim)
397 plt.vlines(exp.attack_start_index * exp.dt, exp.y_lim[0], exp.y_lim[1], color='red', linestyle='dashed', linewidth=2)
398 plt.vlines(exp.recovery_index * exp.dt, exp.y_lim[0], exp.y_lim[1], colors='green', linestyle='dotted', linewidth=2)
399
400 plt.fill_between(t + 0.5, t * 0 - exp.s.a, t * 0 - exp.s.b, facecolor='green', alpha=0.3)
401 plt.ylabel(exp.y_label)
402 plt.xlabel("Time [s]")
403 plt.legend(ncol=2)
404
405
406def sim_strategies(exps, plot_time_series):
407
408 for exp in exps:
409
410 strategies = {}
411 # Declare strategies we want to simulate
412 strategies = { # 'none': simulate_no_recovery,
413 'ssr': simulate_ssr,
414 'oprp-close': simulate_oprp_cl,
415 'oprp-open': simulate_oprp_ol,
416 'lqr': simulate_LQR}
417
418
419 result = {}
420 result[exp.name] = {}
421 exp_rst = result[exp.name]
422 for strategy in strategies:
423 exp.model.reset()
424 exp_rst[strategy] = {}
425 simulate = strategies[strategy]
426 # Simulate strategy
427 profiling_data = simulate(exp, strategy)
428 # Store data
429 save_exp_data(exp, exp_rst, strategy, profiling_data)
430 recovery_complete_index = exp_rst[strategy]['recovery_complete_index']
431 final_state = exp_rst[strategy]['states'][recovery_complete_index].tolist()
432
433
434
435 # Begin plots
436 if plot_time_series:
437 str_plot = ['ssr', 'oprp-open', 'lqr']
438 plot_ts(str_plot, exp, exp_rst)
439 str_plot = ['oprp-open', 'oprp-close']
440 plot_ts(str_plot, exp, exp_rst)
441 plt.show()
442
443
444
445# Main function
446def main():
447 plot_time_series = True
448 # Import the system and simulation settings. See the settings.py file
449 # This classes have the simulation parameters such as the safe regions
450 from settings import motor_speed_bias, quadruple_tank_bias, f16_bias, aircraft_pitch_bias, boeing747_bias, quadrotor_bias, rlc_circuit_bias
451 exps = [motor_speed_bias]
452 sim_strategies(exps, plot_time_series)
453
454
455if __name__ == "__main__":
456 main()
457
458
An user can change the attack characteristics (e.g., detection delay).
1'''
2This file has the simulation parameters for several linear systems presented in the paper.
3'''
4
5import numpy as np
6import sys
7sys.path.append(sys.path[0] + '/../')
8from cpsim.models.linear.motor_speed import MotorSpeed
9from cpsim.models.linear.quadruple_tank import QuadrupleTank
10from cpsim.models.linear.F16 import F16
11from cpsim.models.linear.aircraft_pitch import AircraftPitch
12from cpsim.models.linear.boeing747 import Boeing
13from cpsim.models.linear.heat import Heat
14from cpsim.models.linear.platoon import Platoon
15from cpsim.models.linear.rlc_circuit import RlcCircuit
16from cpsim.models.linear.quadrotor import Quadrotor
17from cpsim.models.linear.lane_keeping import LaneKeeping
18from cpsim.attack import Attack
19from cpsim.formal.strip import Strip
20# --------------------- motor speed -------------------
21class motor_speed_bias:
22 # Experiment name
23 name = 'motor_speed_bias'
24 # Maximum simulation steps
25 max_index = 500
26 # Discretization time
27 dt = 0.02
28 # Reference vector
29 ref = [np.array([4])] * 501
30 # Noise characteristics
31 noise = {
32 'process': {
33 'type': 'white',
34 'param': {'C': np.array([[0.01, 0], [0, 0.01]])}
35 }
36 }
37 # Import system dynamics
38 model = MotorSpeed('bias', dt, max_index, noise)
39 # Control input constraints
40 control_lo = np.array([0])
41 control_up = np.array([50])
42 model.controller.set_control_limit(control_lo, control_up)
43 # Attack characteristics
44 attack_start_index = 150
45 bias = np.array([-1])
46 attack = Attack('bias', bias, attack_start_index)
47 # Attacks detection instant. This value comes from the detector.
48 recovery_index = 200
49
50 # OPR parameters: strip vector l and parameters a, b
51 s = Strip(np.array([-1, 0]), a=-4.2, b=-3.8)
52 P_given = 0.95
53 max_recovery_step = 140
54 # plot
55 ref_index = 0
56
57 # Kalman filter parameters for the OPR-CL
58 kf_C = np.array([[0, 1]]) # This parameter depends on the attack characteristics
59 k_given = 40 # This is K. Maximum number of recovery steps
60 kf_R = np.diag([1e-7])
61
62 # Parameters for the RTR-LQR
63 safe_set_lo = np.array([4, 30])
64 safe_set_up = np.array([5.07, 80])
65 target_set_lo = np.array([3.8, 35.81277766])
66 target_set_up = np.array([4.2, 60])
67 recovery_ref = np.array([4, 41.81277766])
68 Q = np.diag([100, 1])
69 QN = np.diag([100, 1])
70 R = np.diag([1])
71
72 # Plot
73 output_index = 0
74 x_lim = (2.8, 4.2)
75 y_lim = (3.65, 5.2)
76 y_label = 'Rotational speed [rad/s]'
77 strip = (4.2, 3.8)
78
79
80# -------------------- quadruple tank ----------------------------
81class quadruple_tank_bias:
82 # Experiment name
83 name = 'quadruple_tank_bias'
84 # Maximum simulation steps
85 max_index = 300
86 # Discretization time
87 dt = 1
88 # Reference vector
89 ref = [np.array([7, 7])] * 1001 + [np.array([7, 7])] * 1000
90 # Noise characteristics
91 noise = {
92 'process': {
93 'type': 'white',
94 'param': {'C': np.diag([0.05, 0.05, 0.05, 0.05])}
95 }
96 }
97 # Import system dynamics
98 model = QuadrupleTank('test', dt, max_index, noise)
99 # Control input constraints
100 control_lo = np.array([0, 0])
101 control_up = np.array([10, 10])
102 model.controller.set_control_limit(control_lo, control_up)
103 # Attack characteristics
104 attack_start_index = 150
105 bias = np.array([-2.0, 0])
106 attack = Attack('bias', bias, attack_start_index)
107 recovery_index = 160
108
109
110 # OPR parameters: strip vector l and parameters a, b
111 s = Strip(np.array([-1, 0, 0, 0]), a=-14.3, b=-13.7)
112 P_given = 0.95
113 max_recovery_step = 140
114
115 # Kalman filter parameters for the OPR-CL
116 kf_C = np.array([[0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]]) # depend on attack
117 k_given = 40 # This is K. Maximum number of recovery steps
118 kf_R = np.diag([1e-7, 1e-7, 1e-7])
119
120 # Parameters for the RTR-LQR
121 safe_set_lo = np.array([0, 0, 0, 0])
122 safe_set_up = np.array([20, 20, 20, 20])
123 target_set_lo = np.array([13.8, 13.8, 0, 0])
124 target_set_up = np.array([14.2, 14.2, 20, 20])
125 recovery_ref = np.array([14, 14, 2, 2.5])
126 Q = np.diag([1, 1, 0, 0])
127 QN = np.diag([1, 1, 0, 0])
128 R = np.diag([1, 1])
129
130
131 # plot
132 ref_index = 0
133 output_index = 0
134 x_lim = (140, 200)
135 y_lim = (6.7, 9)
136 y_label = 'water level - cm'
137 strip = (7.15, 6.85) # modify according to strip
138
139
140# -------------------- f16 ----------------------------
141class f16_bias:
142 # Experiment name
143 name = 'f16_bias'
144 # Maximum simulation steps
145 max_index = 550
146 # Discretization time
147 dt = 0.02
148 # Reference vector
149 ref = [np.array([0.0872665 * 57.3])] * 801
150 # Noise characteristics
151 noise = {
152 'process': {
153 'type': 'white',
154 'param': {'C': np.eye(4) * 0.002}
155 }
156 }
157 # Import system dynamics
158 model = F16('test', dt, max_index, noise)
159 # Control input constraints
160 control_lo = np.array([-25])
161 control_up = np.array([25])
162 model.controller.set_control_limit(control_lo, control_up)
163 # Attack characteristics
164 attack_start_index = 400
165 bias = np.array([-10])
166 attack = Attack('bias', bias, attack_start_index)
167 recovery_index = 470
168
169
170 # OPR parameters: strip vector l and parameters a, b
171 s = Strip(np.array([0, 0, 1, 0]), a=4.2/57.3, b=5.8/57.3)
172 P_given = 0.95
173 max_recovery_step = 140
174
175 # Kalman filter parameters for the OPR-CL
176 kf_C = np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 0, 1]]) # depend on attack
177 k_given = 40 # This is K. Maximum number of recovery steps
178 kf_R = np.diag([1e-7, 1e-7, 1e-7])
179
180
181 # Parameters for the RTR-LQR
182 safe_set_lo = np.array([300, -5.01717652e-01, 0.04, -1])
183 safe_set_up = np.array([5.02135552e+02,1.01717652e-01, 0.116, 1])
184 target_set_lo = np.array([3.52135331e+02, -1.51738001e-01, 0.0871, 3.05954232e-04])
185 target_set_up = np.array([4.52135331e+02, -0.51738001e-01, 0.0873, 4.05954232e-04])
186 recovery_ref = np.array([4.02135552e+02, -1.01717652e-01, 0.0872665, 1.83150103e-04])
187 Q = np.diag([1, 1, 10000, 10000])
188 QN = np.diag([1, 1, 10000, 10000])
189 R = np.diag([1])
190
191 # Plots
192 ref_index = 0
193 output_index = 0
194 x_lim = (7.9, 8.95)
195 y_lim = (4.5, 6.7)
196 y_label = 'pitch angle - degree'
197 strip = (5.1, 4.9)
198
199
200
201# -------------------- aircraft_pitch ----------------------------
202class aircraft_pitch_bias:
203 # Experiment name
204 name = 'aircraft_pitch_bias'
205 # Maximum simulation steps
206 max_index = 1500
207 # Discretization time
208 dt = 0.02
209 # Reference vector
210 ref = [np.array([0.2])] * (max_index + 1)
211 # Noise characteristics
212 noise = {
213 'process': {
214 'type': 'white',
215 'param': {'C': np.diag([0.0003, 0.0002, 0.0003])}
216 }
217 }
218 # Import system dynamics
219 model = AircraftPitch('aircraft_pitch', dt, max_index, noise)
220 # Control input constraints
221 control_lo = np.array([-20])
222 control_up = np.array([20])
223 model.controller.set_control_limit(control_lo, control_up)
224 # Attack characteristics
225 attack_start_index = 500
226 bias = np.array([-1])
227 attack = Attack('bias', bias, attack_start_index)
228 recovery_index = 550
229
230
231 # OPR parameters: strip vector l and parameters a, b
232 s = Strip(np.array([0, 0, -1]), a=-0.395, b=-0.005)
233 P_given = 0.95
234 max_recovery_step = 140
235
236 # Kalman filter parameters for the OPR-CL
237 kf_C = np.array([[1, 0, 0], [0, 1, 0]]) # depend on attack
238 k_given = 40 # This is K. Maximum number of recovery steps
239 kf_R = np.diag([1e-7, 1e-7])
240
241 # baseline
242 safe_set_lo = np.array([-5, -5, 0])
243 safe_set_up = np.array([5, 5, 1.175])
244 target_set_lo = np.array([0.01624, 0.0, 0.19])
245 target_set_up = np.array([0.05624, 0.01, 0.21])
246 recovery_ref = np.array([0.05624, 0.00028221, 0.2])
247 Q = np.diag([1, 100000, 100000])
248 QN = np.diag([1, 100000, 100000])
249 R = np.diag([1])
250
251 # plot
252 ref_index = 0
253 output_index = 0
254 x_lim = (9.7, 12.7)
255 y_lim = (0, 1.3)
256 y_label = 'pitch - rad'
257 strip = (0.23, 0.17)
258
259
260# -------------------- boeing747 ----------------------------
261class boeing747_bias:
262 # Experiment name
263 name = 'boeing747'
264 # Maximum simulation steps
265 max_index = 800
266 # Discretization time
267 dt = 0.02
268 # Reference vector
269 ref = [np.array([1])] * (max_index + 1)
270 # Noise characteristics
271 noise = {
272 'process': {
273 'type': 'white',
274 'param': {'C': np.eye(5) * 0.02}
275 }
276 }
277 # Import system dynamics
278 model = Boeing('boeing747', dt, max_index, noise)
279 # Control input constraints
280 control_lo = np.array([-30])
281 control_up = np.array([30])
282 model.controller.set_control_limit(control_lo, control_up)
283 # Attack characteristics
284 attack_start_index = 400
285 bias = np.array([-1])
286 attack = Attack('bias', bias, attack_start_index)
287 recovery_index = 430
288
289
290 # OPR parameters: strip vector l and parameters a, b
291 s = Strip(np.array([-1, 0, 0, 0, 0]), a=-1.4, b=-0.6)
292 P_given = 0.95
293 max_recovery_step = 140
294
295 # Kalman filter parameters for the OPR-CL
296 kf_C = np.array([[0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 1]]) # depend on attack
297 k_given = 40 # This is K. Maximum number of recovery steps
298 kf_R = np.diag([1e-7, 1e-7, 1e-7, 1e-7])
299
300 # baseline
301 safe_set_lo = np.array([0.0, -10, -5, -5, -30])
302 #safe_set_up = np.array([1.817344443758, 5, 5, 50, 15])
303 safe_set_up = np.array([1.819, 5, 20, 50, 25])
304 target_set_lo = np.array([0.9, -10, -10, -10, -100])
305 target_set_up = np.array([1.1, 10, 100, 100, 100])
306 recovery_ref = np.array([1, 0, 0, 0, 0])
307 Q = np.diag([100000, 1, 10000, 1, 1])
308 QN = np.diag([100000, 1, 10000, 1, 1])
309 R = np.diag([1]) * 0.1
310
311 # plot
312 ref_index = 0
313 output_index = 0
314 x_lim = (7.8,9.5)
315 y_lim = (0.7, 2.0)
316 y_label = 'Yaw angle - rad'
317 strip = (0.85, 1.15)
318
319def generate_list(dimension, value):
320 temp = []
321 for i in range(dimension):
322 temp.append(value)
323 return temp
324# -------------------- heat ----------------------------
325class heat_bias:
326 # Experiment name
327 name = 'heat'
328 # Maximum simulation steps
329 max_index = 1000
330 # Discretization time
331 dt = 1
332 # Reference vector
333 ref = [np.array([15])] * (max_index + 1)
334 # Noise characteristics
335 noise = {
336 'process': {
337 'type': 'white',
338 'param': {'C': np.eye(45) * 0.0001}
339 }
340 }
341 # Import system dynamics
342 model = Heat('heat', dt, max_index, noise)
343 # Control input constraints
344 control_lo = np.array([-0.5])
345 control_up = np.array([50])
346 model.controller.set_control_limit(control_lo, control_up)
347 # Attack characteristics
348 attack_start_index = 400
349 bias = np.array([-1])
350 attack = Attack('bias', bias, attack_start_index)
351 recovery_index = 500
352
353
354 l = np.zeros((45,))
355 y_point = (45 + 1) // 3 * 2 - 1
356 l[y_point] = -1
357 # OPR parameters: strip vector l and parameters a, b
358 s = Strip(l, a=-15.3, b=-14.7)
359 P_given = 0.95
360 max_recovery_step = 160
361 # plot
362 ref_index = 0
363 output_index = 0
364
365 kf_C = np.zeros((44, 45)) # depend on attack
366 for i in range(44):
367 if i < y_point:
368 kf_C[i][i] = 1
369 elif i >= y_point:
370 kf_C[i][i + 1] = 1
371 k_given = 40 # This is K. Maximum number of recovery steps
372 temp = []
373 for i in range(44):
374 temp.append(1e-7)
375 kf_R = np.diag(temp)
376
377 # baseline
378 temp = generate_list(45, -10)
379 safe_set_lo = np.array(temp)
380
381 temp = generate_list(45, 1000)
382 safe_set_up = np.array(temp)
383
384 temp = generate_list(45, -10)
385 temp[y_point] = 14.8
386 target_set_lo = np.array(temp)
387
388 temp = generate_list(45, 1000)
389 temp[y_point] = 15.2
390 target_set_up = np.array(temp)
391
392 temp = generate_list(45, 0)
393 temp[y_point] = 15
394 recovery_ref = np.array(temp)
395
396 temp = generate_list(45, 1)
397 temp[y_point] = 1
398 Q = np.diag(temp)
399 QN = np.diag(temp)
400 R = np.diag([1]) * 10000
401
402
403
404
405
406# -------------------- platoon ----------------------------
407class platoon_bias:
408 # Experiment name
409 name = 'platoon'
410 # Maximum simulation steps
411 max_index = 800
412 # Discretization time
413 dt = 0.02
414 # Reference vector
415 ref = [np.array([2])] * (max_index + 1)
416 # Noise characteristics
417 noise = {
418 'process': {
419 'type': 'white',
420 'param': {'C': np.eye(7) * 0.0001}
421 }
422 }
423 # Import system dynamics
424 model = Platoon('Platoon', dt, max_index, noise)
425 # Control input constraints
426 control_lo = np.array([-5, -5, -5, -5])
427 control_up = np.array([5, 5, 5, 5])
428 model.controller.set_control_limit(control_lo, control_up)
429 # Attack characteristics
430 attack_start_index = 400
431 bias = np.array([-1])
432 attack = Attack('bias', bias, attack_start_index)
433 recovery_index = 450
434
435
436 # OPR parameters: strip vector l and parameters a, b
437 s = Strip(np.array([-1, 0, 0, 0, 0, 0, 0]), a=-2.3, b=-1.7)
438 P_given = 0.95
439 max_recovery_step = 140
440 # plot
441 ref_index = 0
442 output_index = 0
443 x_lim = (7.5,10)
444 y_lim = (1.5, 2.7)
445 y_label = 'relative distance error with car 1 and 2'
446 strip = (1.9, 2.1)
447
448 kf_C = np.array([[0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0],
449 [0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 0, 1]]) # depend on attack
450 k_given = 40 # This is K. Maximum number of recovery steps
451 kf_R = np.diag([1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7])
452
453 # baseline
454 safe_set_lo = np.array([1, 1, 1, 0, 0, 0, 0])
455 safe_set_up = np.array([2.5, 3, 3, 5, 5, 5, 5])
456 target_set_lo = np.array([1.95, 0, 0, 0, 0, 0, 0])
457 target_set_up = np.array([2.05, 5, 5, 5, 5, 5, 5])
458 recovery_ref = np.array([2, 2, 2, 2, 2, 2, 2])
459 Q = np.diag([1, 1, 1, 1, 1, 1, 1])
460 QN = np.diag([1, 1, 1, 1, 1, 1, 1])
461 R = np.diag([1, 1, 1, 1])
462
463
464# -------------------- rlc_circuit ----------------------------
465class rlc_circuit_bias:
466 # Experiment name
467 name = 'rlc_circuit'
468 # Maximum simulation steps
469 max_index = 800
470 # Discretization time
471 dt = 0.02
472 # Reference vector
473 ref = [np.array([3])] * (max_index + 1)
474 # Noise characteristics
475 noise = {
476 'process': {
477 'type': 'white',
478 'param': {'C': np.eye(2) * 0.0001}
479 }
480 }
481 # Import system dynamics
482 model = RlcCircuit('rlc_circuit', dt, max_index, noise)
483 # Control input constraints
484 control_lo = np.array([-15])
485 control_up = np.array([15])
486 model.controller.set_control_limit(control_lo, control_up)
487 # Attack characteristics
488 attack_start_index = 400
489 bias = np.array([-1])
490 attack = Attack('bias', bias, attack_start_index)
491 recovery_index = 415
492
493
494 # OPR parameters: strip vector l and parameters a, b
495 s = Strip(np.array([-1, 0]), a=-3.2, b=-2.8)
496 P_given = 0.95
497 max_recovery_step = 140
498 # plot
499 ref_index = 0
500 output_index = 0
501 x_lim = (7.9, 8.7)
502 y_lim = (2.7, 4.1)
503 y_label = 'Capacitor Voltage - V'
504 strip = (2.8, 3.2)
505
506 kf_C = np.array([[0, 1]]) # depend on attack
507 k_given = 40 # This is K. Maximum number of recovery steps
508 kf_R = np.diag([1e-7])
509
510 # baseline
511 safe_set_lo = np.array([2.5, -1])
512 safe_set_up = np.array([4, 0.5])
513 target_set_lo = np.array([2.95, -1])
514 target_set_up = np.array([3.05, 1])
515 recovery_ref = np.array([3, -1.52863266e-05])
516 Q = np.diag([1, 1])
517 QN = np.diag([1, 1])
518 R = np.diag([1])
519
520
521# -------------------- quadrotor ----------------------------
522class quadrotor_bias:
523 # Experiment name
524 name = 'quadrotor'
525 # Maximum simulation steps
526 max_index = 1000
527 # Discretization time
528 dt = 0.02
529 # Reference vector
530 ref = [np.array([4])] * (max_index + 1)
531 # Noise characteristics
532 noise = {
533 'process': {
534 'type': 'white',
535 'param': {'C': np.eye(12) * 0.08}
536 }
537 }
538 # Import system dynamics
539 model = Quadrotor('quadrotor', dt, max_index, noise)
540 # Control input constraints
541 control_lo = np.array([-50])
542 control_up = np.array([50])
543 model.controller.set_control_limit(control_lo, control_up)
544 # Attack characteristics
545 attack_start_index = 400
546 bias = np.array([-2])
547 attack = Attack('bias', bias, attack_start_index)
548 recovery_index = 410
549
550
551 # OPR parameters: strip vector l and parameters a, b
552 s = Strip(np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1]), a=-4.5, b=-3.5)
553 P_given = 0.95
554 max_recovery_step = 140
555 # plot
556 ref_index = 0
557 output_index = 5
558 x_lim = (7.9, 8.9)
559 y_lim = (3.5, 6.2)
560 y_label = 'Altitude - m'
561 strip = (4.3, 3.7)
562
563 # kf_C = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) # depend on attack
564 kf_C = np.zeros((11, 12))
565 for i in range(11):
566 kf_C[i][i] = 1
567 # print(kf_C)
568 k_given = 40 # This is K. Maximum number of recovery steps
569 kf_R = np.diag([1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7, 1e-7])
570
571 # baseline
572 safe_set_lo = np.array([-1, -1, -1, -10, -10, -10, -10, -10, -10, -10, -10, 3.5])
573 safe_set_up = np.array([10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 7.8])
574 target_set_lo = np.array([-1, -1, -1, -10, -10, -10, -10, -10, -10, -10, -10, 3.9])
575 target_set_up = np.array([10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 4.1])
576 recovery_ref = np.array([5.67886532e-03, 5.25493934e-03, -1.59956078e-03, 1.21647831e-03,
577 2.57637592e-04, 1.17194568e-03, -2.24887084e-01, 1.84248778e-01,
578 -2.22306362e-03, -5.65196133e-01, 4.69398702e-01, 4])
579 Q = np.diag([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
580 QN = np.diag([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
581 R = np.diag([1])
582
583
584# -------------------- lane keeping ----------------------------
585class lane_keeping:
586 # Experiment name
587 name = 'lane_keeping_bias'
588 # Maximum simulation steps
589 max_index = 250
590 # Discretization time
591 dt = 0.05
592 # Reference vector
593 ref = [np.array([0, 0, 0, 0])] * (max_index + 1)
594 # Noise characteristics
595 noise = {
596 'process': {
597 'type': 'white',
598 'param': {'C': np.eye(4) * 0.002}
599 }
600 }
601 # Import system dynamics
602 model = LaneKeeping('test', dt, max_index, noise)
603 # Control input constraints
604 control_lo = np.array([-0.261799])
605 control_up = np.array([0.261799])
606 model.controller.set_control_limit(control_lo, control_up)
607 # Attack characteristics
608 attack_start_index = 100
609 bias = np.array([-0.6, 0, 0, 0])
610 attack = Attack('bias', bias, attack_start_index)
611 recovery_index = 130
612
613
614 # OPR parameters: strip vector l and parameters a, b
615 s = Strip(np.array([1, 0, 0, 0]), a=-0.05, b=0.05)
616 P_given = 0.95
617 max_recovery_step = 1150
618 # plot
619 ref_index = 0
620 output_index = 0
621 x_lim = (4.5, 9.3)
622 y_lim = (-0.1, 0.6)
623 y_label = 'lateral error - m'
624 strip = (-0.05, 0.05)
625
626 kf_C = np.array([[0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
627 k_given = 100 # This is K. Maximum number of recovery steps
628 kf_R = np.diag([1e-7, 1e-7, 1e-7])
629
630 # baseline
631 safe_set_lo = np.array([-0.03, -0.5, -0.5, -0.5])
632 safe_set_up = np.array([0.55, 1, 1, 1])
633 target_set_lo = np.array([-0.04, -0.5, -0.5, -0.5])
634 target_set_up = np.array([0.04, 0.5, 0.5, 0.5])
635 recovery_ref = np.array([0, 0.00726603, 0.00359684, -0.00704901])
636 Q = np.diag([100, 1, 1, 1])
637 QN = np.diag([100, 1, 1, 1])
638 R = np.diag([1])
Reference:
High-fidelity Simulators
Since CPSim is a python package, it can be used in conjunction with any simulator that can be called from python. Especially, many high-fidelity simulators are controlled through python node of ROS, such as Gazebo, SVL, CARLA, and AirSim.
This example demonstrates how to use the toolbox to recover an autonomous vehicle in the SVL simulator. The vehicle suffers from an IMU sensor attack, deviates from its own lane, and even enters the oncoming lane, as shown in Figure (a). To apply the lqr recovery controller [2]_ after detecting the attack, we need to integrate the toolbox with the SVL simulator. Since there is a ROS bridge communicating with the simulator, we load the toolbox in a ROS node, which is responsible for recovering the vehicle from the attack within a safety deadline. Figure (b) shows that vehicle returns to its lane during the recovery process. Figure (c) shows that the recovery controller steers the vehicle to a safe region, the road shoulder, to avoid a collision after recovery.

Finally, we show the demonstration video here.
Robotic Vehicle Testbed
Autonomous vehicles are a type of CPS that rely on sensor information to perform tasks such as path tracking and lane keeping. We built scaled autonomous vehicles, measuring 24 cm in length and 19 cm in width, as testbeds to evaluate the proposed attack detection and recovery methods.

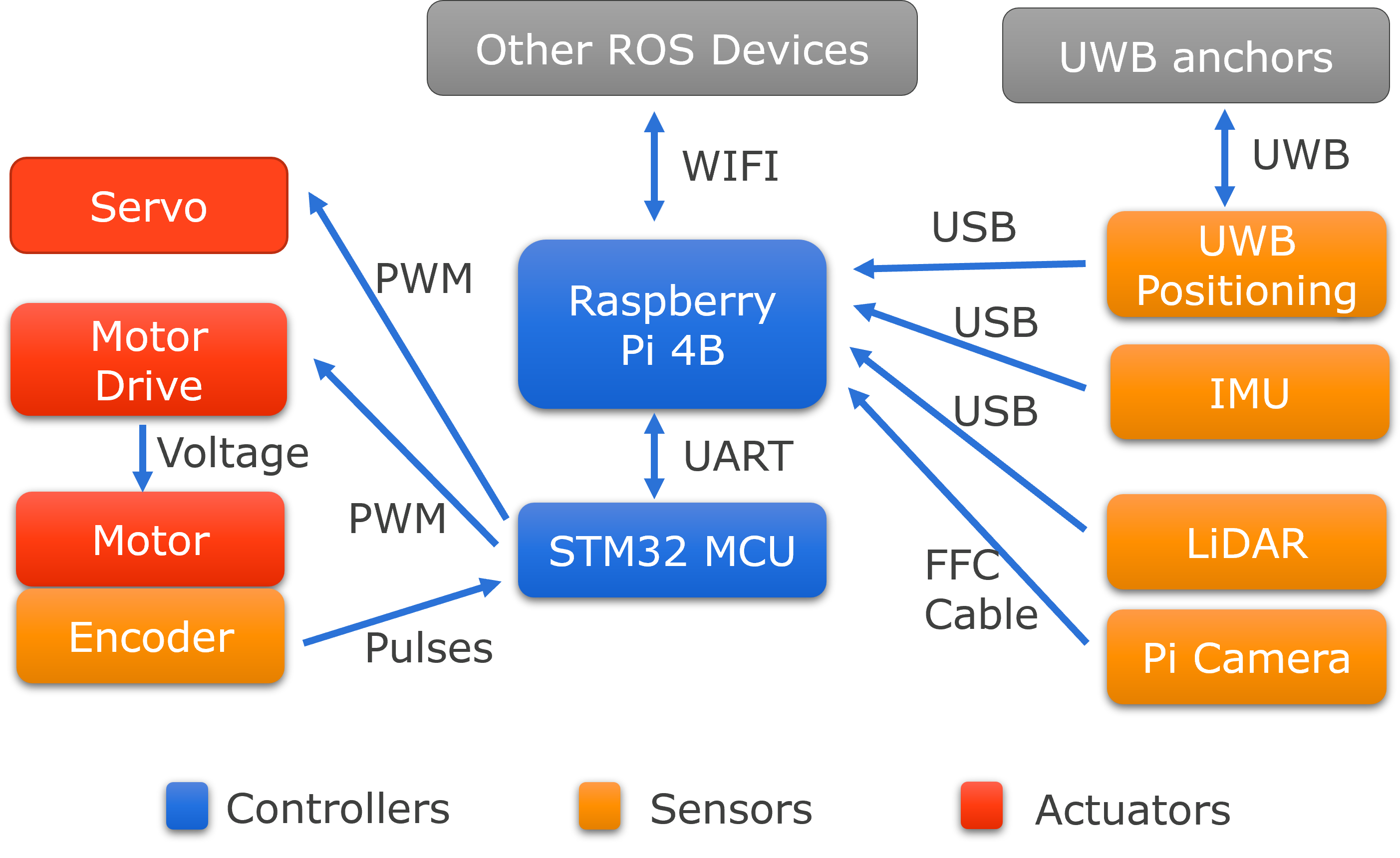
Autonomous vehicles sense states and environments, make decisions, and control mobility. Our robotic vehicle testbeds, whose hardware architecture is shown in the following figure, simulate these functions through the following stages:
Perception: Our testbed is equipped with an Inertial Measurement Unit (IMU), Ultra-wideband (UWB), and encoder sensors that measure attitude, position, and velocity, respectively. We can also use cameras and LiDAR to collect additional environmental data. However, these sensors are vulnerable to sensor attacks.
Decision Making: A Raspberry Pi with Robot Operating System (ROS2) serves as the main controller. It collects sensor data, estimates vehicle states, and generates control signals. The system uses different controllers for longitudinal and lateral control. For cruise control, a PID controller stabilizes the testbed’s velocity based on encoder feedback. For lane keeping, a Stanley Controller uses the front axle as its reference point, considering both heading error and cross-track error. We can also deploy the proposed attack detection and recovery algorithms on this system.
Control: An STM32 microcontroller with FreeRTOS system receives control signals from the Raspberry Pi through a Universal Asynchronous Receiver/Transmitter (UART) protocol. Running a real-time operating system, it performs time-sensitive tasks such as generating Pulse Width Modulation (PWM) signals to drive actuators.
Actuator: The actuator stage includes components such as motors and servos that execute vehicle movements according to control signals.
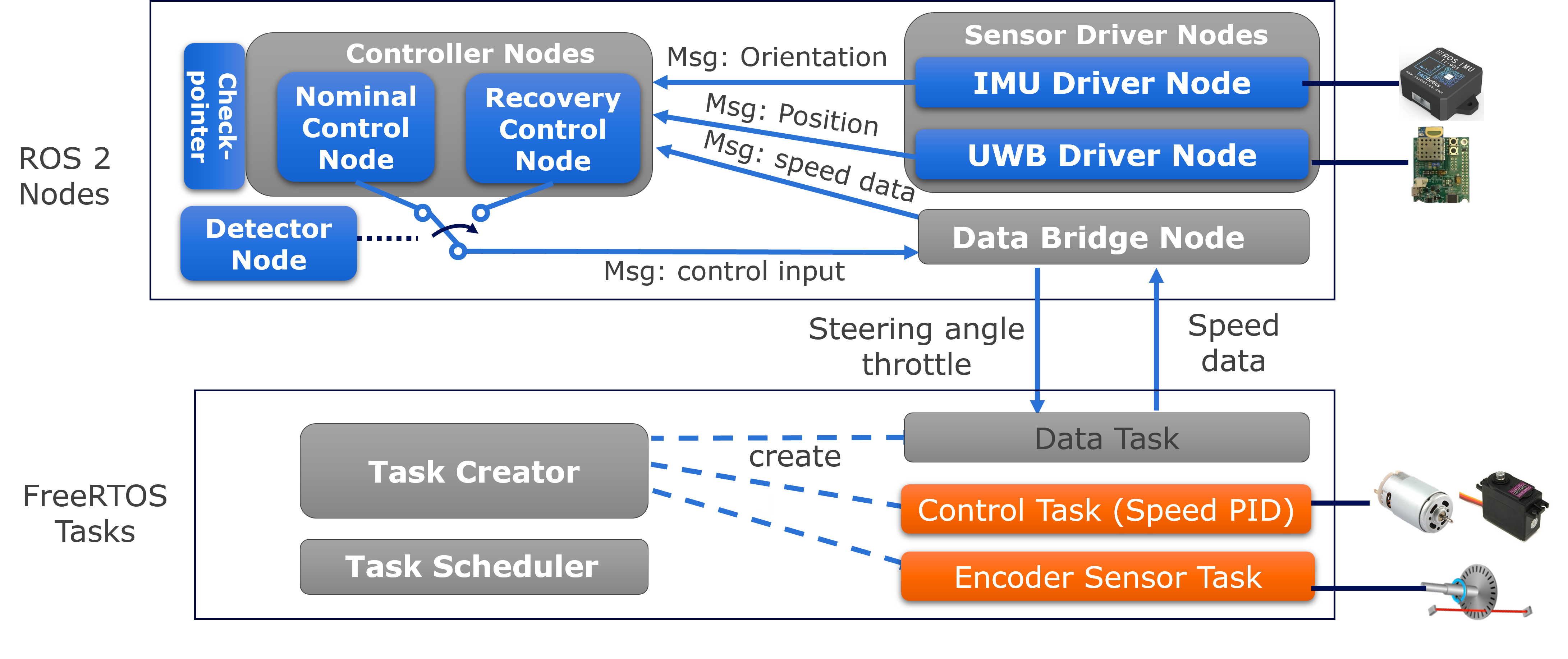
To demonstrate the toolbox usage, we show a real-time attack recovery on SVL high-fidelity simulator. We implement the LQR-based attack recovery method [2]_ on the robotic vehicle testbed, and the design is illustrated in this figure:
Autonomous vehicles perform lateral control to track paths provided by path planning modules. High-fidelity models of vehicle dynamics are complex, non-linear, and discontinuous. However, to reduce computational complexity, path tracking controllers typically consider a simplified lateral dynamics model of the vehicle (as shown in the following equation). This model approximates dynamic effects to improve tracking performance.
Here, \(c_f\) and \(c_r\) represent cornering stiffness for the front and rear tires; \(l_f\) and \(l_r\) are the distances from the front and rear tires to the vehicle’s center of gravity; \(I_z\) is the vehicle’s moment of inertia; and \(v_x\) is the longitudinal velocity. The system states are lateral distance from the path (\(y\)), lateral error rate (\(\dot{y}\)), yaw error (\(\psi\)), and yaw error rate (\(\dot{\psi}\)). The control input is the front wheel steering angle ( \(\delta\)).
To achieve path tracking, we implement the Stanley lateral controller in ROS. The control law is expressed as \(\delta(t)=\psi(t)+\tan ^{-1}\left(\frac{k y(t)}{v_x(t)}\right)\). The yaw error (\(\psi\)) is obtained from the IMU sensor, and the lateral distance from the path (\(y\)) is obtained from the UWB sensor for indoor use. In the absence of sensor attacks, the controller can perform path tracking tasks with good performance. The attacker launches an attack on the IMU sensor, reducing the value of \(\psi\) by 0.60 radians from the start of the attack, with a detection delay of 60 control steps. Figure (a) shows the attack result as detected by the detector. Subsequently, our proposed method begins controlling the vehicle back to the safe zone, as shown in Figure (c).

Finally, we show the demonstration video here.